A New Open Source Flan 20B with UL2
Note: Views here are personal opinions and do not represent that of my employer.
TL;DR: We release a new open source Flan 20B model that was trained on top of the already open sourced UL2 20B checkpoint.
The full technical details have already been updated to the UL2 paper and the checkpoints have been uploaded to Github. Naturally, this model has the same configuration as the original UL2 20B model, except that it has been instruction tuned with Flan.
We expect that it substantially improve “usability” of the original UL2 model. This model, similar to Flan-T5 and the original UL2 models, are released on Apache license.
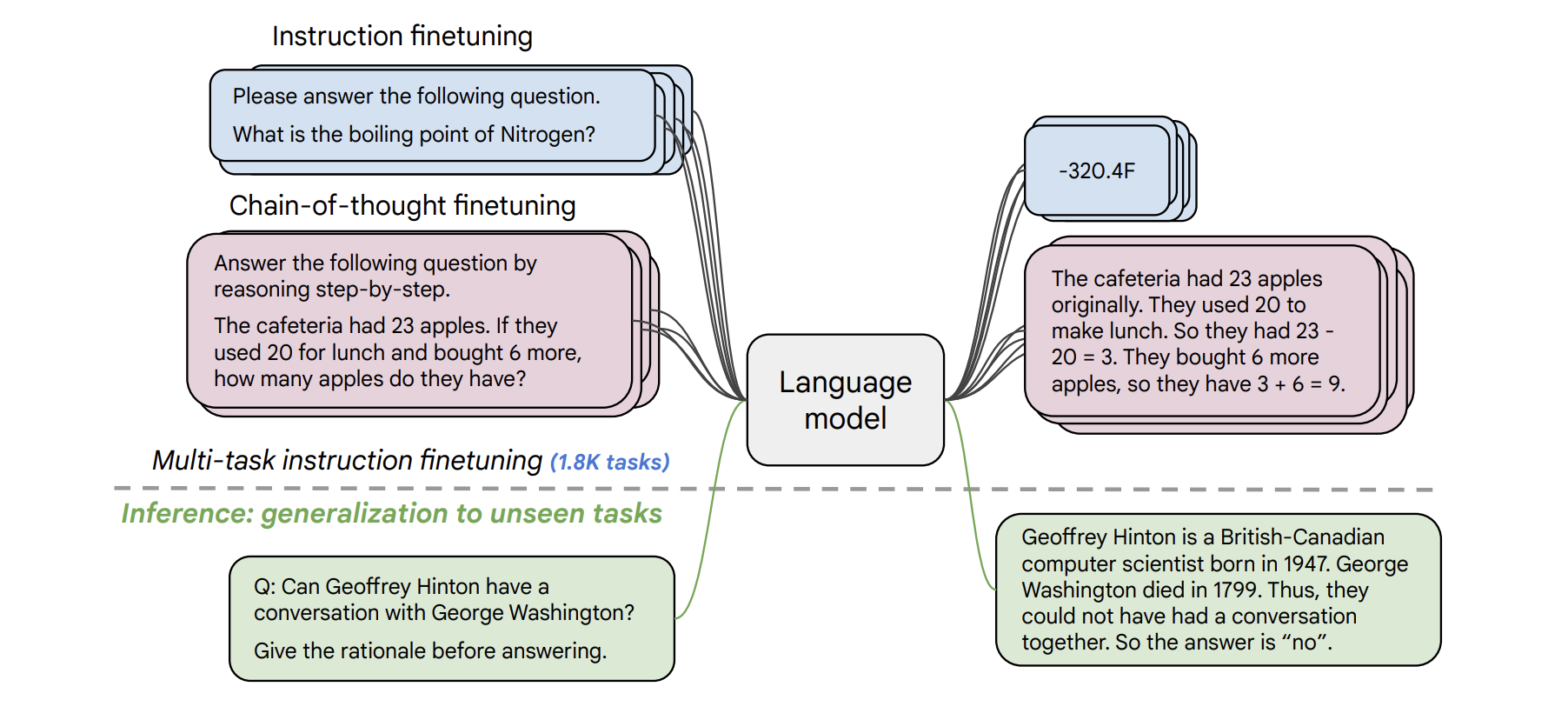
Flan Instruction Tuning
In “Scaling Instruction-Finetuned language models (Chung et al.)” (also referred to sometimes as the Flan2 paper), the key idea is to train a large language model on a collection of datasets. These datasets are phrased as instructions which enable generalization across diverse tasks. Flan has been primarily trained on academic tasks. In Flan2, we released a series of T5 models ranging from 200M to 11B parameters that have been instruction tuned with Flan.
The Flan datasets have also been open sourced in “The Flan Collection: Designing Data and Methods for Effective Instruction Tuning” (Longpre et al.). See Google AI Blogpost: “The Flan Collection: Advancing Open Source Methods for Instruction Tuning”.
Flan 20B with UL2 20B checkpoint
The UL2 20B was open sourced back in Q2 2022 (see “Blogpost: UL2 20B: An Open Source Unified Language Learner”). UL2 20B (~19.5B parameters to be exact) is trained exclusively on the C4 corpus (similar to T5 models). The UL2 model was trained on the new UL2 objective which trains on a mixture-of-denoisers (diverse span corruption and prefix language modeling tasks).
There are two major updates we make to the UL2 20B model with Flan.
The original UL2 model was only trained with receptive field of 512, which made it non-ideal for N-shot prompting where N is large. This Flan-UL2 checkpoint uses a receptive field of 2048 which makes it more usable for few-shot in-context learning.
The original UL2 model also had mode switch tokens that was rather mandatory to get good performance. However, they were a little cumbersome as this requires often some changes during inference or finetuning. In this update/change, we continue training UL2 20B for an additional 100k steps (with small batch) to forget “mode tokens” before applying Flan instruction tuning. This Flan-UL2 checkpoint does not require mode tokens anymore.
Overall Quality
We compare Flan-UL2 20B with other models in the Flan series. We report relative improvements over Flan-T5-XXL. Generally, Flan-UL2 outperforms Flan-T5 XXL on all four setups with an overall decent performance lift of +3.2% relative improvement. Most of the gains seem to come from the CoT setup while performance on direct prompting (MMLU and BBH) seems to be modest at best.

We also note that the overall performance of Flan-UL2 20B approaches the performance of FLAN-PaLM 62B coming in at 49.1 vs 49.9 which is pretty decent considering Flan-UL2 20B is approximately 7-8 times faster than Flan-PaLM 62B.
Chain-of-thought capabilities get much better
A notable outcome of this set of experiments is that the gains on CoT versions of MMLU and BBH tasks have much larger delta, e.g., +7.4% for MMLU and +3.1% and BBH when compared to Flan-T5 XXL. This could be explained by the larger size of the model in general and also the fact that UL2 itself exhibits CoT capabilities (see CoT section of paper). It could be a combination of both.
It is also worth noting that CoT versions of MMLU and BBH still seem worse than direct prompting. However, these differences also apply to larger Flan-PaLM 62B models (and even sometimes to Flan-PaLM 540B) where the same phenomena is observed. On this note, we also explored self-consistency (Wang et al.) to improve CoT performance and experienced an increase of +6% relative improvement on CoT just by using self-consistency. In this particular standalone experiment, the CoT + self consistency setup outperforms direct prompting by 3% relative improvement.
We did not have time to explore this expanded search space of CoT + Self consistency, so we’re leaving this for future work or an exercise for the readers :).
Limitations of Flan
The Flan series of models are a good compact family of models that are relatively cost-friendly to launch, serve and do many great things with. It’s also free and on an unrestrictive license! However, there are some limitations of Flan-style models. For example, Flan is instruction tuned on primarily academic tasks where outputs are typically short, “academic” and traditional (See tweet by @ShayneRedford). You can imagine Flan to be instruction tuning on “academic tasks for academic tasks”. The debate of whether academic tasks are still relevant is another question altogether.
That said, section 6 “Human usability” in the Flan2 paper shows that Flan still improves usability on open ended generation including creativity, explanation etc.
Overall, the Flan series models have proven to be impactful and useful if you know what you’re using it for. We would like people to keep the above limitation in mind especially when considering what Flan models can do and can’t do.
Expanding the options (and size ceiling) of Flan family of models!
Overall, Flan-UL2 20B model expands the size ceiling of the current Flan-T5 models by approximately 2x, i.e., folks now have the option to go to 20B if they wish. Based on our evals, we think that Flan-UL2 is a better model than Flan-T5 XXL.
It is also the best open source model at the moment on Big-Bench hard and MMLU.
We’re very excited to see what the community does with this new model.
Acknowledgements
Thanks to Mostafa Dehghani (co-lead on UL2), Shayne Longpre, Jason Wei, Hyung Won Chung, Le Hou (co-leads on Flan) and Vinh Tran for feedback on this post. This work was also made possible with the help and contributions from all the authors on the UL2 paper and Flan2 paper.